
Dr. Josh Day
#JuliaLang
#DataScience
#DataViz
#Statistics
#JuliaLang
#DataScience
#DataViz
#Statistics
AdaGrad (PDF) is an interesting algorithm for adaptive element-wise learning rates. First consider a stochastic gradient descent (SGD) update
where is a step size (learning rate) and is the gradient of a noisy objective function. The AdaGrad algorithm replaces the step sizes with a matrix inverse that scales the elements of the gradient:
where . In this form, it is suggested that AdaGrad does not have a learning rate. However, with very basic algebra, the AdaGrad update is
where . That is, if the matrix term producing the adaptive step sizes is considered as a mean instead of a sum, we see that AdaGrad has a learning rate .
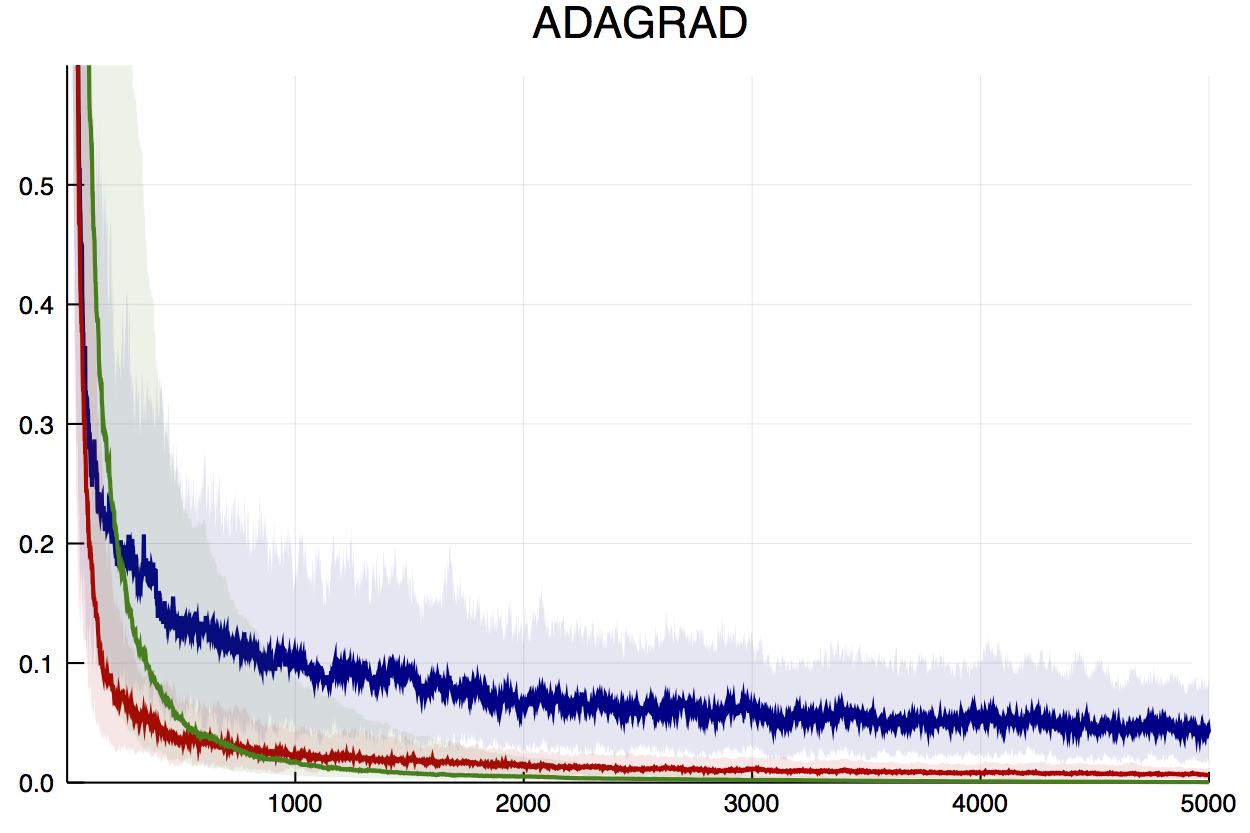
In OnlineStats.jl, different weighting schemes can be plugged into any statistic or model (see docs on Weights). OnlineStats implements AdaGrad in the mean form, which opens up a variety of learning rates to try rather than just the default . The plot below compares three different choices of learning rate. It's interesting to note that the blue line, which uses the above default, is the slowest at finding the optimum loss value.
To try out OnlineStats.ADAGRAD, see StatLearn